[Kafka] Incremental Cooperative Rebalancing in Apache Kafka (Connect)
Kafka Connect와 관련되어 가장 중요한 업데이트라고 생각되는 Incremental Cooperative Rebalancing에 대해서 설명한다.
필자가 가장 중요하다고 생각하는 이유는 Connect 운영하면서 제일 심각한 문제로 생각되던 부분이 개선되었기 때문이다.
개선이 된 부분은 컨슈머의 리밸런싱 동작과 연관이 있다. 그럼 변경되기 이전의 동작방식과 비교하면서 Incremental Cooperative Rebalancing를 이해해보자.
1. 2.3.0 이전 Connect 리밴런싱 전략
이번 글에서 설명하는 Incremental Cooperative Rebalancing는 2.3 버전에서 소개되었다. 그럼 그 이전 버전에서는 커넥트 컨슈머의 리밸런싱이 어떻게 이루어졌는지 보자. 먼저 결론을 말하면 모든 파티션을 모두 반환하고 다시 분배 전략을 짜서 배분한다.
리밸런싱이 일어나는 상황(scale up/ down, rolling restart 등)이 여러가지 이지만 스케일업만 예를 들어 살펴보자.
2개의 컨슈머가 데이터 처리를 하고 있다고 하자. 만약 스케일업을 위해 1개의 컨슈머를 추가하면 어떻게 파티션 분배를 할까?
다음 3개의 그림으로 쉽게 표현하면.
- 가지고 있는 모든 파티션을 반환한다.
- 반환된 파티션을 컨슈머 개수에 의해 적당히 분할한다.
- 실제로 각 컨슈머들에 파티션을 할당한다.
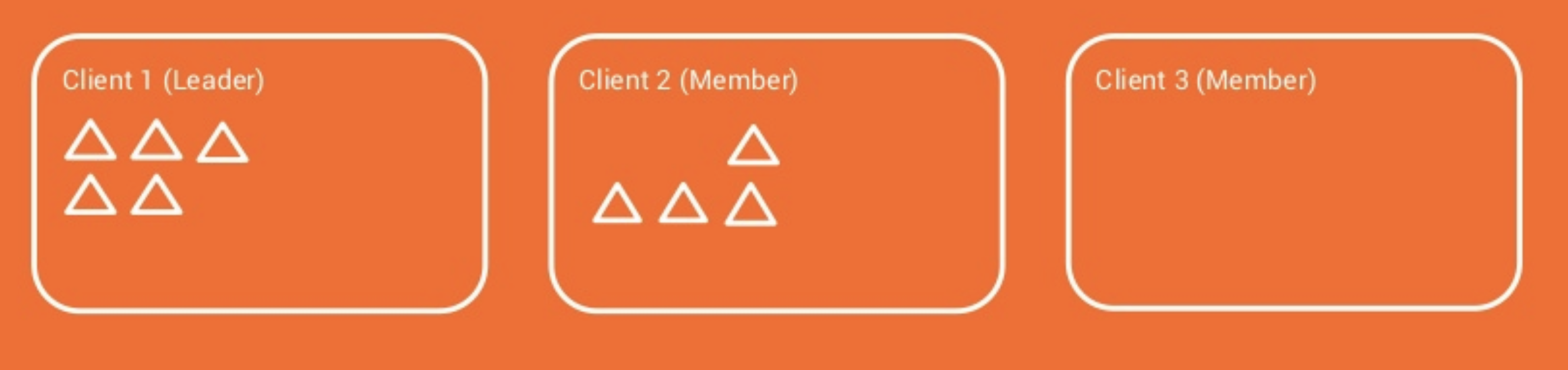

이 방법의 문제는 stop the world가 발생한다는데 있다. 파티션 분배를 하기 위해서 잘 처리하고 있는 파티션들을 모두 정지해야 하고 동작을 멈춘다.
Connect에서는 일반적인 컨슈머를 개발할 때보다 더 심각해 지는 이유는, API를 통해 여러 Task들이 추가/삭제 될 텐데 그 때마다 관계 없는 다른 Task의 작업도 모두 정지했다가 분배 후 다시 시작한다.
2. Incremental Cooperative Rebalancing
그럼 개선된 리밸런싱은 어떻게 동작할까? 자세한 설명 전에 리밸런싱의 이름에 포함된 두 단어의 내포된 의미를 살펴보면 이해하는데 도움이 된다.
- Incremental (증가하는, 증대하는)
- 최종 리밸런싱 상태에 이르기까지 점진적으로 개선된다. 리밸런싱 단계를 거칠 때 한번에 최종 단계에 이를 필요가 없다. 적은 숫자의 연속적인 리밸런싱 작업으로 최종적으로 균형적인 파티션 분배를 하면된다.
- Cooperative (협력적인)
- 컨슈머 그룹에 포함된 각 컨슈머는 재분배를 위해서 자발적으로 리소스를 해제한다.
리밸런싱 이름에서 유추할 수 있는 것은 한번에 분배가 이루어졌던 기존 방법과는 달리 여러 단계에 걸쳐서 이루어진다는 점이다. 그리고 기존에 할당된 모든 파티션을 해제하고 분배하는 것이 아니라 분배를 필요로 하는 일부 파티션만 각 컨슈머가 자발적으로 해제를 하고 해당 파티션만 분배가 이루어진다는 것이다.
그럼 실제 케이스를 보면서 이해해보자. 참고로 Incremental Cooperative Rebalancing은 KIP-415에 소개된 기능이다.
리밸런싱의 모든 케이스를 살펴보면 분량이 길어지니 자세한 사항은 confluent와 KIP 문서를 살펴보고 여기서는 새로운 worker(컨슈머)가 추가되는 scale up 상황만 보자.
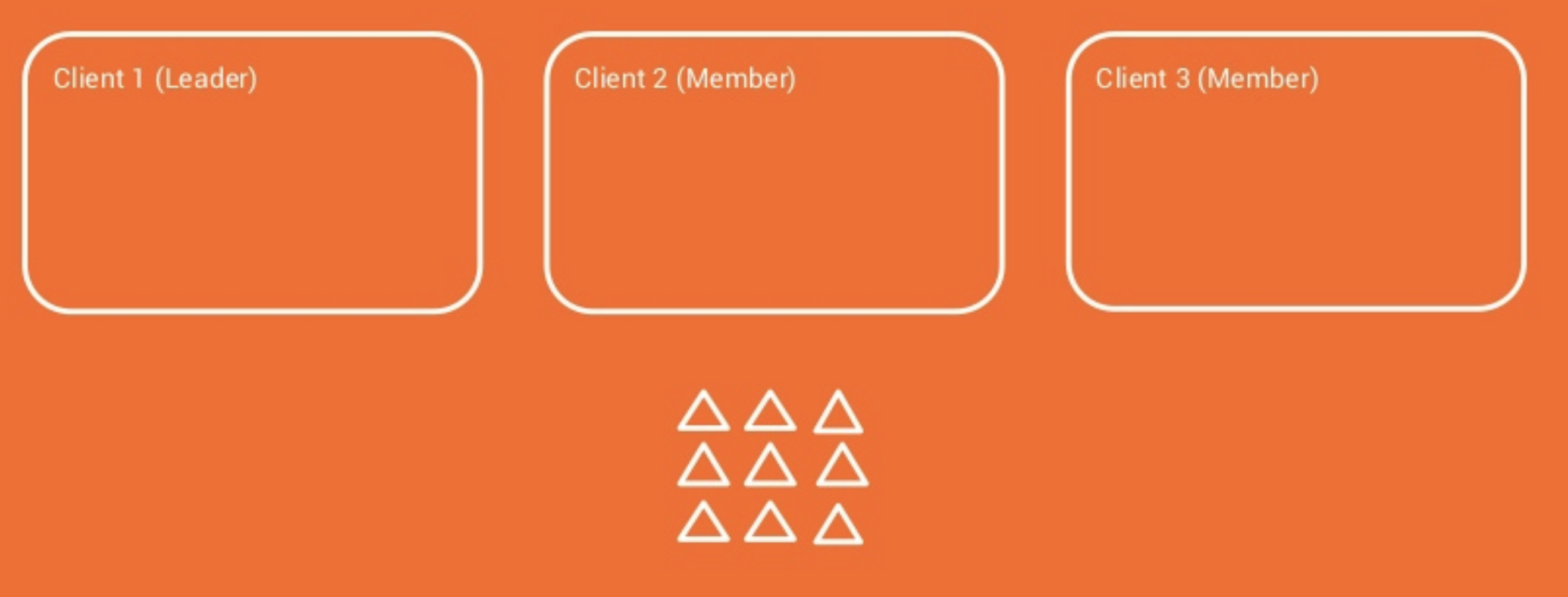
아래 그림에서 리밸런싱은 2단계로 이루어졌다.
- 새로운 컨슈머에게 할당해 줄 파티션을 기존 컨슈머가 자발적으로 해제한다.
- 해제된 2개의 파티션을 새로운 컨슈머에게 할당한다.

기존 리밸런싱과 다르게 2단계로 나누어 이루어졌다. 그런데 큰 차이점은 1단계에서 해제하지 않은 파티션은 정지하지 않고 계속 작업을 수행한다. stop the world가 발생하지 않는 이유이다.
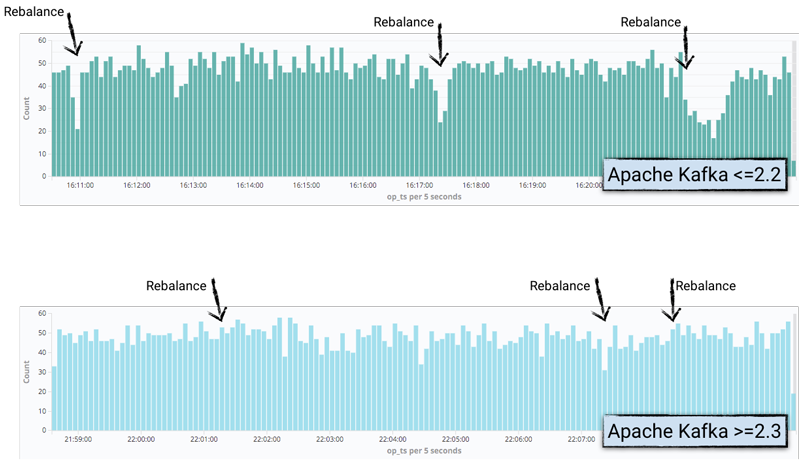
아래 그림은 2.3 이전과 이후 각각 Elasticsearch Connector를 수행한 결과를 보여준다. kibana 그래프로서 x축은 시간, y축은 해당 시간에 저장된 데이터 수이다. 2.3이전 버전에서는 리밸런싱이 일어날 때 저장된 데이터가 급격히 줄었다가 늘어남을 보인다. 이유는 stop the world로 인해 해당 시간에 데이터 처리를 하지 못했기 때문이다. 그런데 2.3 이후 버전에서는 리밸렁싱이 일어나도 아주 크게 데이터 저장 수가 줄어들지 않는다. 몇개의 파티션이 리밸런싱 되어서 정지하겠지만 모든 파티션 작업이 정지되는 것은 아니기 때문이다.
3. Rolling restart를 위한 리밸런싱 유예
Incremental Cooperative Rebalancing에서는 추가적인 특이사항이 있다. Plugin 재배포 등으로 connect의 Rolling restart를 위해 리밸런싱 유예 시간을 둔 점이다. scheduled.rebalance.max.delay.ms 설정값으로 조정한다. Connect 서버가 정지되면 바로 해당 서버가 가진 파티션을 리밸런싱 하는 것이 아니라 특정 시간 (기본 5분) 동안 리밸런싱을 유예한다.
다시 해당 커넥트 서버가 재 시작되었을 때, 기존에 할당되었던 파티션 그대로 다시 작업을 진행할 수 있다. 뿐만 아니라 다른 커넥트 서버가 수행하던 작업에는 영향이 없다.
4. 결론
이번 글에서는 Incremental Cooperative Rebalancing에 대해서 정리를 했다. 2.3 버전이면 꽤 시간이 지났고, 해당 기능이 나왔을 때 굉장히 만족했던 것에 비해 정리 글이 늦었다. 필자도 Connect 서버를 사용하는데 기존에 Task를 추가할 때마다 리밸런싱을 위해 모든 파티션이 정지되어서 처리량이 떨어지는 것을 볼 때 가장 심각한 버그로 여겼다. 대량 데이터 처리를 하는데 있어 너무 치명적이었기 때문이다. 그래서 필자는 2.3 버전에서 Connect에 대한 많은 개선 중 제일 중요한 업데이트로 Incremental Cooperative Rebalancing 꼽는다.
오늘 글에서는 Connect의 리밸런싱 동작에 대해서만 한정해서 설명했다. 2.4 버전에서는 기존 Consumer의 리밸런싱 전략에도 변화가 있었다. 큰 골자는 Incremental Cooperative Rebalancing과 같다. 다만 약간의 차이가 있다. 향후에 Consumer의 리밸런싱 동작에 대해 설명하고 차이점에 대해서도 추가로 분석해 보도록 하겠다.
참고문서
- Design and Implementation of Incremental Cooperative Rebalancing
- Incremental Cooperative Rebalancing in Apache Kafka: Why Stop the World When You Can Change It?
Design and Implementation of Incremental Cooperative Rebalancing - Confluent
Because of stop-the-world, application tasks get interrupted only for most of them to receive the same resources after rebalancing. In this technical deep dive, we’ll discuss the proposition of Incremental Cooperative Rebalancing as a way to alleviate st
www.confluent.io
Incremental Cooperative Rebalancing in Apache Kafka
Learn how load balancing works, the challenges of existing load balancing protocols, and how Incremental Cooperative Rebalancing allows large-scale deployment of Kafka clients.
www.confluent.io