HBase 활용을 위한 기본 개념
이번에는 HBase에 대한 글을 처음으로 쓴다.
필자는 Kafka로 들어온 다양한 데이터를 여러 저장소에 적재하는 기능을 개발하고 있다. 이번에 HBase에 데이터 적재 기능을 추가하게 되었다. 개발을 진행하면서 HBase 활용 측면에서 알아야 하는 기본적인 내용을 정리함으로써 HBase를 도입하려고 하시는 분들에게 참고사항이 되었으면 한다.
1. 아키텍처
먼저 HBase의 아키텍처를 살펴본다. 두 가지 측면으로 나누어서 정리한다.
- 데이터 구성
- HBase 서버 아키텍처
데이터 구성을 알면 HBase로 데이터 적재 시 RowKey, Column Family(이하 컬럼패밀리) 등의 데이터 구조 설계에 도움이 된다. 그리고 HBase의 서버 아키텍처를 알면 클라이언트가 데이터 저장/ 조회할 때의 데이터 흐름을 이해할 수 있다.
1.1. 데이터 구성
데이터는 아래와 같은 구조로 구성된다.
- 테이블
- 로우
- 컬럼
- 셀
일단 먼저 알아야 할 것은 HBase는 칼럼 지향 데이터베이스이다. 그래서 많이 사용하는 RDB와 구조 자체가 다르다.
RDB는 대부분 B+ 트리 등으로 인덱스를 구성해서 데이터를 조회할 때 활용한다. 그에 비해 HBase는 LSM 트리 구조를 사용한다. HBase로 저장되는 데이터는 로그 파일 형태로 순차적으로 저장하며, 백그라운드에서 로그 파일들을 단계적으로 병합한다. 백그라운드에서 MemStore, WAL(write-ahead log), HFile로 나누어 저장된 데이터가 어떻게 병합되는지가 궁금하면 HBase 완벽 가이드 8장의 내용을 참고하면 도움이 된다.
로그 파일 형태로 데이터를 저장하는 파일을 나누는 기준이 되는 것은 컬럼패밀리이다. RDB의 컬럼과는 다르게 HBase는 컬럼이 컬럼패밀리:퀄리파이어 형태로 저장되는데 같은 컬럼패밀리가 한 파일로 묶인다. 그래서 데이터를 저장할 때 어떤 컬럼들이 어떤 컬럼패밀리로 묶이는지도 중요하다.
컬럼에 대한 이야기를 먼저 꺼냈는데 다시 앞서 소개한 구성요소로 돌아가 보자. 4개의 데이터 구성요소들은 아래 코드와 같은 관계를 갖는다. 코드로 설명한 이유는 어떤 값으로 정렬되고 묶이는지 한눈에 보기 위해서다.
코드를 보면 RowKey, Column이 SortedMap에 포함됨으로써 정렬됨을 알 수 있다. RowKey가 정렬된다는 점은 데이터 적재 구조를 설계할 때 가장 중요한 부분이다. 아래에서 키 설계에 대해 추가로 설명을 한다.
1.2. HBase 서버 아키텍처
서버 구성은 먼저 [그림 1]으로 살펴보자.
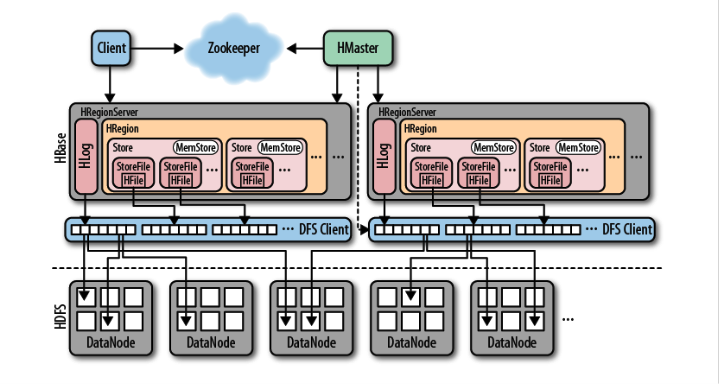
구성 요소로 HMaster, HRegionServer, Zookeeper가 있다. 각각의 역할을 정리해본다.
- HMaster
- RegionServer에 Region 할당
- 클러스터에 있는 모든 RegionServer들을 Zookeeper를 통해 관리
- HRegionServer
- Region 관리
- 데이터 읽기/ 쓰기 요청 처리
- Zookeeper
- RegionServer의 heartbeat 받음 (정상 동작 확인)
- .META. 서버의 path 관리
- 클라이언트는 Zookeeper에 접근해서 RegionServer를 찾는 과정을 거친다.
주의 깊게 볼 부분은 데이터 읽기/쓰기 요청 처리를 HRegionServer가 한다는 점이다. 클라이언트는 데이터를 쓸 때 HRegionServer에 직접 쓴다. 다르게 말하면 HBase 클러스터의 HRegionServer에 모두 접근 가능해야 한다.
여기서 의문점이 하나 들 수 있다. HBase 클라이언트가 객체를 초기화할 때 Zookeeper 서버만 넣지 않냐는 의문이다.
아래 코드는 HBase Connection 객체를 만드는 예이다.
그 이유는 Zookeeper의 역할에 있다. Zookeeper는 .META. 서버의 path를 관리한다. .META. 서버로부터 HBase 클러스터의 리전 정보를 얻을 수 있기 때문이다. 참고로 리전에 저장될 데이터는 RowKey 통해서 나뉜다.
2. 데이터 설계
그럼 HBase를 활용할 때 적재할 데이터 구조는 어떻게 설계하는 것이 좋을까? HBase를 활용하는 측면에서 가장 중요하게 생각해 볼 요소이다.
[1.1절]에서 설명한 데이터 구조를 다시 살펴보자.
아래 [그림 2]는 HBase 데이터를 조회할 때 어떤 구조에서 필터링했는지에 따라 결정되는 성능이다.
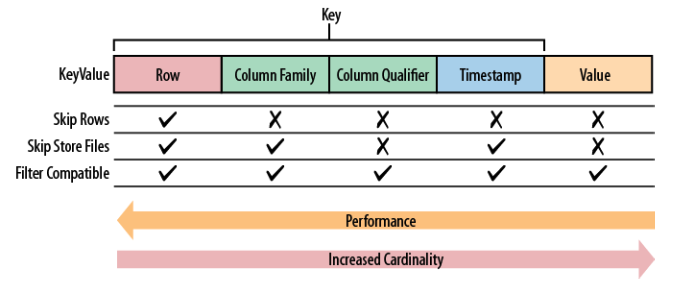
데이터 조회 성능은 키의 오른쪽 필드를 사용하는 쿼리일수록 떨어진다. 결국 RowKey를 어떻게 구성할지가 핵심이다.
HBase는 별도의 인덱스로 RowKey 하나를 찾아가는 방식이 아니라 정렬된 RowKey에서 스캔하는 방법으로 데이터를 조회한다. 그래서 RowKey를 어떤 데이터의 조합으로 구성해서 조회가 빠르게 될 수 있도록 필러링 가능한 구조로 만드는 것이 중요하다.
아래 표는 RowKey를 구성하는 예를 나타낸다. (HBase 완벽 가이드 발췌)
데이터는 이메일 받은 편지함을 HBase를 사용해 저장할 때의 RowKey 구성이라 가정한다.
| RowKey | 설명 |
| <사용자_ID> | 주어진 사용자 ID의 모든 메세지 스캔 |
| <사용자_ID>-<날짜> | 주어진 사용자 ID로 특정 날짜에 받은 모든 메세지 스캔 |
| <사용자_ID>-<날짜>-<메세지_ID> | 주어진 사용자 ID로 특정 날짜에 받은 특정 메세지의 모든 구성 요소 스캔 |
데이터를 어떤 조건으로 조회해야 하는 서비스인지 먼저 분석을 한 다음에 HBase RowKey 설계를 해야 한다.
그리고 RowKey 이외에 추가적으로 검토할 점은 컬럼패밀리 지정 부분이다.
앞서 설명했듯이 HBase는 컬럼패밀리 단위로 파일을 나눠서 저장한다. 따라서 RowKey와 함께 쿼리에 포함할 컬럼들을 같은 컬럼패밀리로 묶으면 불필요하게 탐색해야 할 파일의 수가 줄어들어 성능을 향상할 수 있다.
3. 결론
이 글에서는 HBase의 기본적인 아키텍처와 데이터 저장 방식에 대해서 살펴봤다. HBase의 아키텍처에 따라 활용할 때는 어떤 설계 방식을 따라야 할 지도 키 설계를 예를 들며 설명했다. 필자는 HBase를 살펴보면서 LSM 트리 구조 및 HFile 병합 방식 등에 대해서 더 궁금증이 생겼다. 추가적인 검토를 하고 다른 글로 또 설명하도록 하겠다.
참고 문서