[ksqlDB] concepts
ksqlDB 공식 문서를 보면 concepts 항목에 ksqlDB를 이해하기 위한 주요 개념들을 설명하고 있다. 이 글을 concepts 공식 문서의 내용을 간략하게 요약했다(글에 포함된 사진은 ksqlDB 공식 문서에서 가져왔다). 전체적인 개념만 파악하는 용도로 이 글을 활용하고 자세한 사항은 ksqlDB의 공식문서를 읽어보자.
1. ksqlDB란?
전통적인 RDB를 활용한 방식이 아닌 Event 처리 관점으로 어플리케이션을 개발하기 위한 목적으로 만들어졌다. Event는 시간의 흐름 안에서 특정 시점에 발생하고 기록된 데이터이다. ksqlDB는 Event를 쉽게 사용하게 한다는 목적을 지향한다. 그리고 Event의 저장 및 처리 기능을 카프카 플랫폼에 두고 그 위에 추상화하는 형태로 만들어졌다.
Event streaming 시스템을 만들기 위해 카프카 오픈소스는 아래와 같은 구조로 개발되어 있다. 스트리밍 데이터 처리를 ETL 구조로 나누었을 때, 각 영역의 역할을 담당하는 카프카 컴포넌트가 아래 그림에 기술되어 있다.
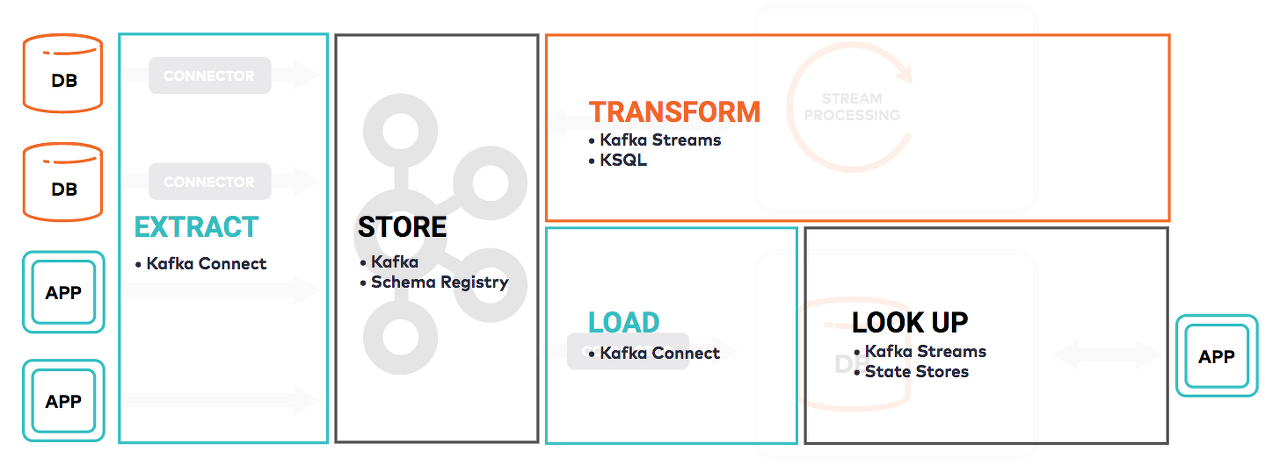
ksqlDB의 목표는 카프카 오픈소스의 각 컴포넌트들이 하고 있던 역할을 보다 통합 및 재구조화하여 스트림 프로세싱을 보다 쉽게 처리할 수 있게 하는데 있다.
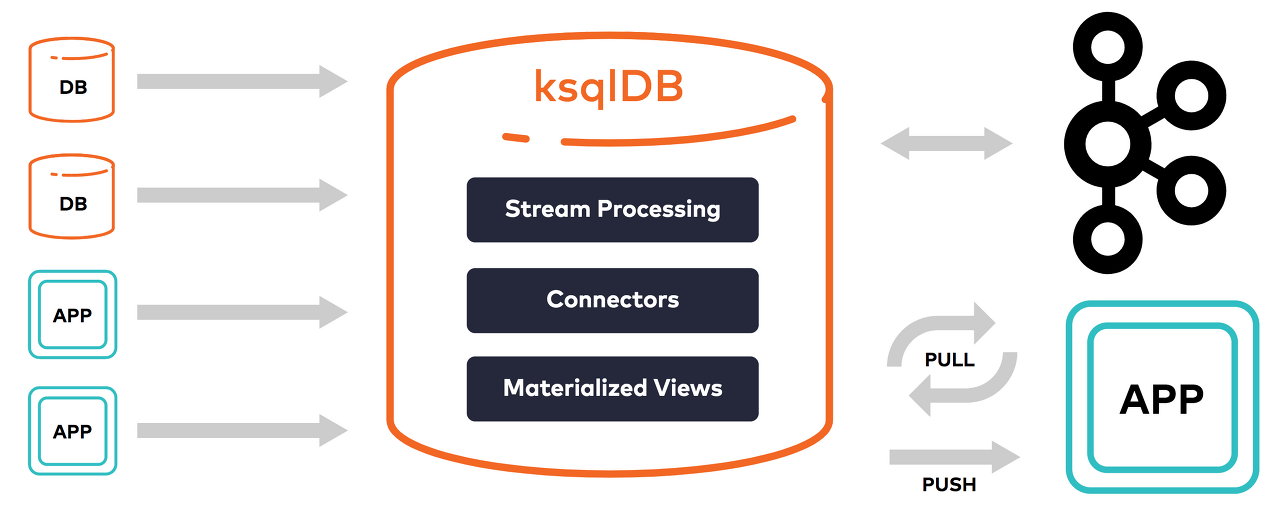
1.1. Stream Processing
ksqlDB는 카프카의 토픽을 새로 만들거나 기존 토픽을 특정 스키마로 강제하여 컬렉션을 만든다. 그리고 리얼타임으로 새롭게 만들어진 컬렉션에 Event의 transforming, filtering, joining, aggregation 결과를 업데이트한다. 이 작업은 무한히 계속해서 수행하게 되며, 정지를 위해서는 명시적으로 종료시켜야한다.
새로운 컬렉션의 스키마는 ksqlDB의 SELECT 문으로 추정해서 바로 만든다. 그리고 ROWTIME, ROWPARTITION, ROWOFFSET 등은 카프카 토픽에 기록될 때 같이 만들어진다. 예를 들면 아래와 같은 쿼리이다.
// rock_songs이라는 원천 데이터가 있다고 가정합니다.
CREATE STREAM rock_songs (artist VARCHAR, title VARCHAR)
WITH (kafka_topic='rock_songs', partitions=2, value_format='avro');
// 파생 테이블의 스키마는 SELECT 문에서 바로 추정하여 만듭니다.
CREATE STREAM title_cased_songs AS
SELECT artist, UCASE(title) AS capitalized_song
FROM rock_songs
EMIT CHANGES;1.2. Materialized View
어떤 데이터베이스던지 쿼리 형태로 현재의 데이터를 조회한다. ksqlDB도 key/value 모델로 카프카에 데이터를 저장하며 쿼리의 결과 데이터를 제공한다. ksqlDB가 제공하는 Materialized View는 전체 데이터를 탐색하여 만들지 않고, 변경 데이터에 대해서만 평가하여 업데이트한다. 새로운 event가 들어왔을 때, 미리 지정한 aggregation function을 수행하여 새로운 값을 view에 반영한다. Materialized View는 뒤에 설명할 pull query와 관련이 있다.
1.3. Query
ksqlDB의 쿼리는 Pull, Push 형태가 존재한다.
- Pull 쿼리는 전통적인 데이터베이스와 같이 "현재"의 특정 데이터를 조회하는 형태이다.
- Push 쿼리는 실시간으로 들어오는 Event를 구독하는 형태이다.
1.3.1. Pull Query
Pull Query는 전통적인 데이터베이스의 쿼리와 같이 "현재"의 데이터를 가져오고 커넥션이 종료된다. 일반적으로 동기식 제어흐름을 따른다. Pull Query는 앞서 설명한 Materialized View에 구체화된 현재 데이터를 가져온다.

1.3.2. Push Query
Push Query는 실시간으로 변경되는 데이터를 구독하는 형태이다. Push Query도 SQL과 유사한 언어를 사용하여 표현된다. 특정 키를 대상으로 데이터를 받을 수도 있고, 키 조회에 국한되어 사용하지 않을 수도 있다. 데이터의 결과형태가 다를 뿐 필터, 선택, 그룹, 조인 등의 기능도 동일하게 제공한다. 다만 Push Query의 결과는 카프카에 백업하지 않는다. 결과의 영속적 저장을 위해서는 CREATE TABLE AS SELECT 또는 CREATE STREAM AS SELECT를 사용하여 파생 스트림, 테이블을 생성해야 한다.

1.4. Join
ksqlDB가 지원하는 Join 종류를 타입(stream, table)별로 정리한 표이다.
TYPEINNERLEFT OUTERRIGHT OUTERFULL OUTER기타
| Type | INNER | LEFT OUTER | RIGHT OUTER | FULL OUTER | |
| Stream-Stream | Windowed | Supported | Supported | Supported | Supported |
| Table-Table | Non-windowed | Supported | Supported | Supported | Supported |
| Stream-Table | Non-windowed | Supported | Supported | Not Supported | Not Supported |
- LEFT OUTER : leftRecord-NULL
- RIGHT OUTER : rightRecord-NULL
- FULL OUTER : leftRecord-NULL, rightRecord-NULL
1.4.1. Join의 제약사항
Table의 경우 반드시 PRIMARY KEY에 의해서만 파티션이 되며, 키의 재분배가 불가능하므로 반드시 primary key로 조인을 수행해야 한다.
그리고 파티션에 대한 제약사항이 존재한다.
- 조인 대상 컬럼은 반드시 동일 스키마여야 한다.
- 만약 동일 스키마가 아니라면 (ex: INT vs STRING) 타입 변환을 통해서 조인을 할 수 있다.
- 조인되는 양쪽 레코드를 반드시 동일한 수의 파티션이어야 한다.
- 동일한 파티션 수를 맞춰주기 위해서 파티션 수를 지정하여 재분할된 Stream을 만들 수 있다.
- 조인되는 양쪽 레코드는 동일한 파티셔닝 전략이이여야 한다.
- Producer에서 별다른 설정을 하지 않고 사용한다면 default partitioner로 사용한다.
- default partitioner의 간략한 로직 설명.
- 레코트 키를 해싱하여 파티션 지정
- 키가 없을 경우 round-robin으로 파티션 지정
1.5. Time and Windows
Stream에는 시간의 개념이 필수적이다. ksqlDB에서 사용하는 window 개념을 설명하기에 앞서 스트리밍 처리에서의 Time의 의미론적 분류에 대해 알아본다.
- Event-time
- Event가 발생한 시간. Event가 생성되었을 때 레코드에 시간을 기록해야 한다.
- Ingestion-time
- 카프카 브로커가 레코드에 기록한 시간 (입수 시간).
- Event 발생 후 바로 카프카에 기록했다면 시간 차가 크지 않겠지만, Event 발생 Source에서 기록한 것이 아닌 카프카 브로커에서 기록한 시간이다.
- Processing-time
- 스크림 처리를 위해 레코드를 소비했을 때의 시간.
1.5.1. 카프카의 Timestamp assignment
토픽의 설정에 message.timestamp.type이 있다. 해당 설정은 2가지의 타입을 가진다.
- CreateTime (default)
- Producer에 의해 레코드 timestamp가 기록.
- LogAppendTime
- 카프카 브로커에 레코드가 전달될 때, 브로커의 로컬 시간으로 timestamp 기록.
1.5.2. Window
SUM과 같은 aggregation을 지속적으로 수행할 수 있고 그에 의해 구분된 시간 경계를 window라고 한다. window는 WINDOWSTART와 WINDOWEND 사이의 시간 간격을 의미한다. WINDOWSTART과 WINDOWEND는 aggregation 쿼리 결과로서 별도의 컬럼으로 존재한다.

1.5.3. Window types
| Window type | Behavior | Description |
| Tumbling Window | Time-based | Fixed-duration, non-overlapping, gap-less windows |
| Hopping Window | Time-based | Fixed-duration, overlapping windows
|
| Session Window | Session-based | Dynamically-sized, non-overlapping, data-driven windows
|
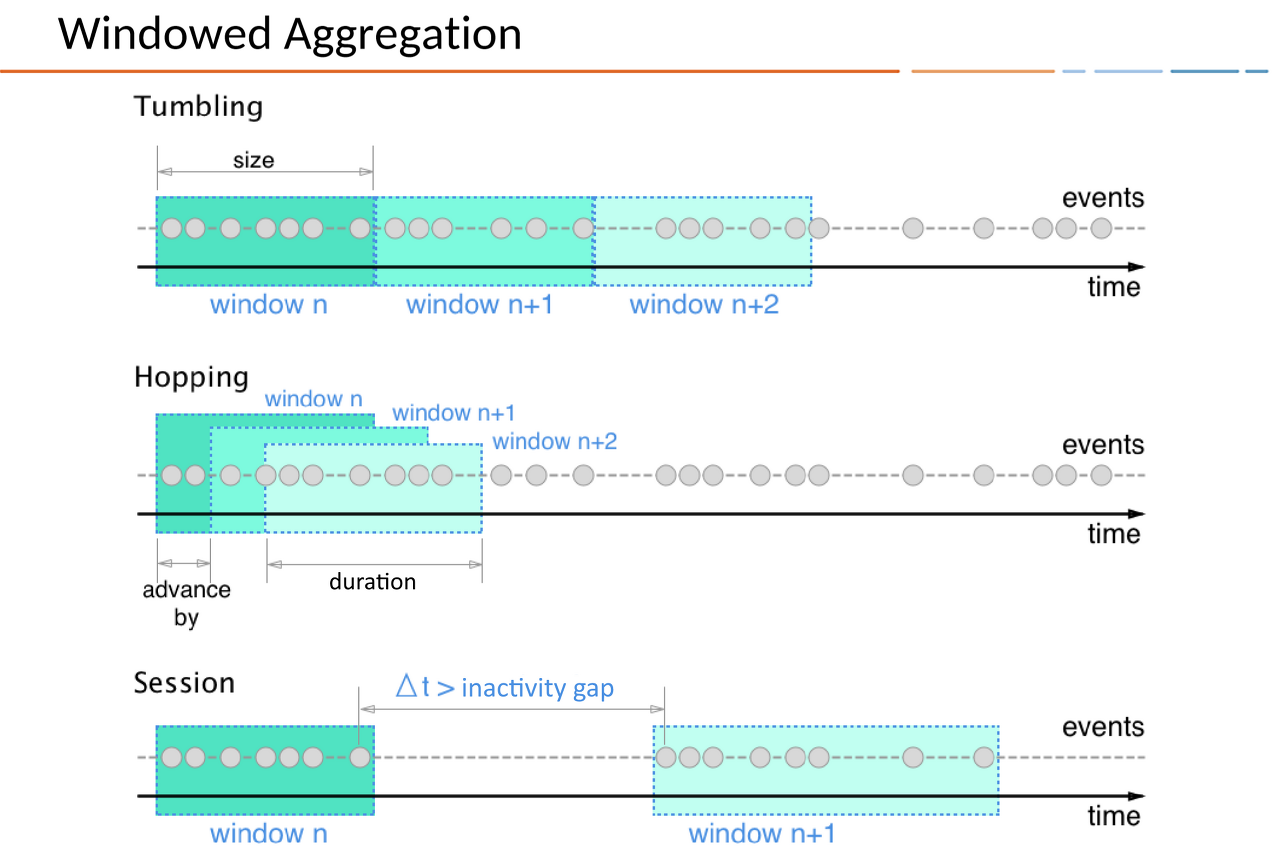
Window type별로 Query문의 예제는 아래와 같다.
-- Hopping
SELECT regionid, COUNT(*) FROM pageviews
WINDOW HOPPING (SIZE 30 SECONDS, ADVANCE BY 10 SECONDS)
WHERE UCASE(gender)='FEMALE' AND LCASE (regionid) LIKE '%_6'
GROUP BY regionid
EMIT CHANGES;
-- Tumbling
SELECT orderzip_code, TOPK(order_total, 5) FROM orders
WINDOW TUMBLING (SIZE 1 HOUR) GROUP BY order_zipcode
EMIT CHANGES;
-- session
SELECT regionid, COUNT(*) FROM pageviews
WINDOW SESSION (60 SECONDS)
GROUP BY regionid
EMIT CHANGES;1.5.4. Out-of-order events
스트리밍 데이터는 데이터가 늦게 도착할 수 있다. 예를 들면, 네트워크 상황으로 발생한 이벤트가 카프카에 보내지 못하고 있다가 늦게 도착하는 경우를 들 수 있다. 이와 같은 지연 데이터에 대해 window는 어떤 처리를 하는지 추가로 알아보자.
ksqlDB는 window를 생성할 때, 지연된 레코드의 유예 기간(grace period)를 설정할 수 있다. 아래 쿼리와 같이 window를 설정할 때, GRACE PERIOD를 설정하여 유예 기간을 명시한다. GRACE PERIOD를 설정하지 않는다면 default 값으로 24시간을 유예한다.
SELECT orderzip_code, TOPK(order_total, 5) FROM orders
WINDOW TUMBLING (SIZE 1 HOUR, GRACE PERIOD 2 HOURS)
GROUP BY order_zipcode
EMIT CHANGES;1.5.5. Window retention
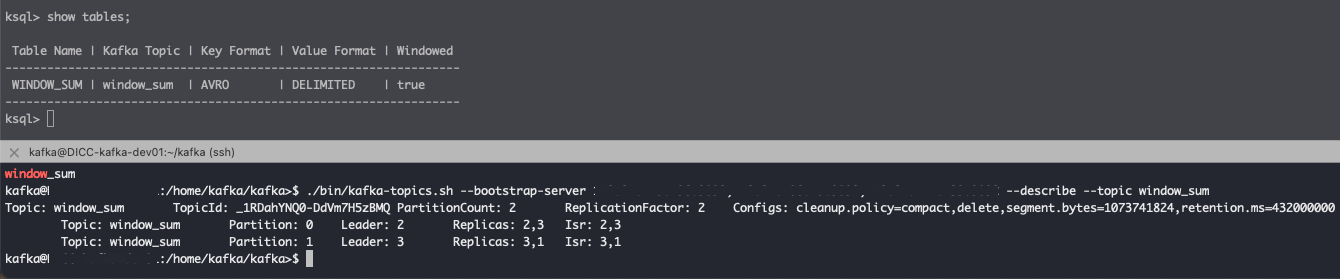
Window의 마지막 주제는 retention이다. Retention은 window의 보존기간이다. Window는 ksqlDB의 수용량이 있기에 무한히 저장할 수 없다. 그래서 pull query를 통한 대화식 어플리케이션을 개발할 때 Retention을 고려하여 사용해야 한다.
CREATE TABLE pageviews_per_region AS
SELECT regionid, COUNT(*) FROM pageviews
WINDOW HOPPING (SIZE 30 SECONDS, ADVANCE BY 10 SECONDS, RETENTION 7 DAYS, GRACE PERIOD 30 MINUTES)
WHERE UCASE(gender)='FEMALE' AND LCASE (regionid) LIKE '%_6'
GROUP BY regionid
EMIT CHANGES;아래 그림은 RETENTION을 설정하지 않은 Table의 카프카 토픽 정보를 조회해 본 결과이다. retention.ms 값이 설정되어 있듯이 기본 카프카 retention을 따르는 것을 알 수 있다.