Big Data/Kafka
[Kafka] Introducing ksqlDB
devidea
2019. 11. 21. 13:59
이번글에서는 2019-11-20 날짜에 confluent 블로그에 게시된 글을 토대로 ksqlDB를 전반적으로 소개하고자 한다.
아래 글의 내용은 대부분 confluent 블로그의 내용을 이해한 만큼 정리한 것이다.
내용에서 ksqlDB의 내부 아키텍처 부분은 제외했는데 ksqlDB를 테스트해보고 아키텍처 설명과 함께 다른 글로 정리하려고 한다.
ksqlDB에서 특징을 2가지로 구분해서 설명한다. Pull queries, Connector Management.
Feature 1 : Pull queries
지속적인 스트림 형태로 들어오는 데이터에서 특정 키 값으로 조회하려는 것은 불가능하다.
지속적으로 변화하는 스트림에서 데이터를 밀어낸다는 의미로 push queries라는 명칭으로 부르기로 한다. 이러한 쿼리는 영구적으로 실행되며 새로운 변경이 발생할 때마다 결과를 업데이트 한다.
ksqlDB는 전통적인 RDB에 구체화한 테이블 형태의 데이터를 통합해준다.
push queries는 기능적인 측면에서 특정 시점 쿼리 point-in-time queries 또는 쿼리가능 상태 queryable state 라고 한다.
예제로 설명한 케이스는 드라이버 위치를 기록하는 앱으로 들었다.
위치를 변경해 가면서 현재 시점의 특정 드라이버의 위치를 얻으려고 할 때 ksqlDB로 쿼리를 날릴 수 있다.
SELECT ride_id, current_latitude, current_longitude
FROM ride_locations
WHERE ROWKEY = ‘6fd0fcdb’;
+-----------+-----------------------+-----------------------+
|RIDE_ID |CURRENT_LATITUDE |CURRENT_LONGITUDE |
+-----------+-----------------------+-----------------------+
|45334 |37.7749 |122.4194 |
+-----------+-----------------------+-----------------------+
여기서 EMIT CHANGES를 추가하면 현재 드라이버에 대한 위치 변경 기록을 지속적으로 받을 수 있다.
SELECT ride_id, current_latitude, current_longitude
FROM ride_locations
WHERE ROWKEY = ‘6fd0fcdb’
EMIT CHANGES;
+-----------+-----------------------+-----------------------+
|RIDE_ID |CURRENT_LATITUDE |CURRENT_LONGITUDE |
+-----------+-----------------------+-----------------------+
|45334 |37.7749 |122.4194 |
|45334 |37.7749 |122.4192 |
|45334 |37.7747 |122.4190 |
|45334 |37.7748 |122.4188 |
이러한 기능이 전혀 없었던 것은 아니고 ksqlDB의 특이점은 스트림 프로세싱 쿼리를 RDB를 활용할 수 있다는 점이다.
Feature 2 : Connector management
Kafka Connect는 스트림 데이터를 RDB를 포함한 다른 여러 Repository로 지속적으로 전달해 주는 기능을 가지고 있다.
Kafka, Connect, KSQL은 각자 독립적인 인터페이스를 가지고 있었는데 ksqlDB는 이를 직접 컨트롤해서 Connector를 실행할 수 있다.
CREATE SOURCE CONNECTOR rider_profiles WITH (
'connector.class' = 'io.confluent.connect.jdbc.JdbcSourceConnector',
'connection.url' = 'jdbc:postgresql://postgres:5432/postgres',
'key' = 'profile_id',
...
);
ksqlDB를 개발한 근본적인 이유를 스트림 데이터를 처리할 때 만들어야 하는 시스템의 복잡성 때문이라 설명한다.
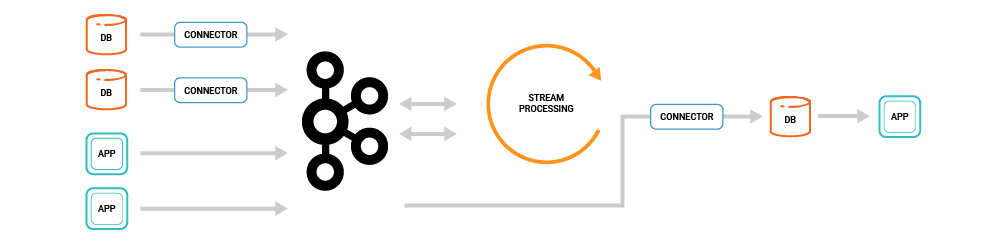
위 그림으로 Extract, Store streams, Transform, Load, Store and query를 수행하기 위해 복잡한 구성을 만들어야 한다고 예를 든다.
위 동작을 간단히 풀어서 설명하면,
기존 RDB에 쌓이는 데이터를 Kafka로 입수(source connector) 하고, Kafka에 있는 데이터를 분석 요구사항에 맞게 프로세싱(KSQL, Kafka Streams 등)하고 다시 RDB로 재적재(sink connector) 한 다음 적재한 내용을 서비스에서 활용한다.
설명한 동작은 ETL 작업으로 다시 구조화 하면 아래 그림이 된다.

이런 과정의 문제점으로 든 점이 여러 시스템들을 각각 관리하는데 부담이 된다가 요점이다.
그래서 ksqlDB는 RDB를 통한 CRUD 만으로 구조를 간단히 한다고 설명한다.
기존 구조에서 벗어나 Kafka, ksqlDB만 유지하면 동일한 처리가 가능하다.
애플리케이션 개발에 이벤트 스트림 처리를 만들 때, 복잡성을 최대한 배재하고 간단한 아키텍처를 설계하고자 했다.
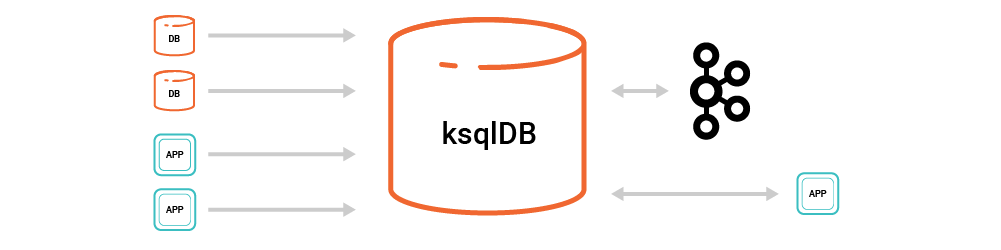
한계점
-
읽기 후 쓰기 일관성을 보장하지 않으며, 주요 데이터를 위한 OLTP 저장소로 사용하기에는 힘들다.
-
모든 그룹의 가용성을 확보하는데 시간이 걸린다. (데이터 복제 때문인 듯 하다)
-
pull query 성능은 최대 수천 QPS. 큰 데이터 사이즈에서는 RockDB의 성능에 따라간다.
개인적인 평가
글을 읽고선 ksqlDB의 첫 느낌 정도로 표현해보자면 서비스 개발할 때, 스트림 처리를 도입하기 위해 최대한 편리하게 쓸 수 있는 방향으로 컨셉을 잡았다는 생각이 들었다.
ksql도 kafka stream을 sql 만으로 간편히 처리해 보자는 개념이었고, ksqlDB는 ksql + connect를 통합해서 스트림 데이터의 특정 시점의 값도 sql도 편리하게 찾을 수 있어요라고 강조한다.
"스트림 처리를 위해서 ksqlDB만 쓰면 되게 해보겠습니다."라고 말하고 싶은 듯 하다.
confluent가 원하는 방향으로 가려면 내부적으로는 아직 발전할 부분이 많은 듯 하다. 하나만 쓰세요라고 말하려면 가용성, 성능이 어느정도 돼야 서비스에 바로 적용하려는 시도가 생길테니깐.
데이터 엔지니어 측면에서는 서비스 개발자에게 이것만 쓰세요라고 말할 때, 그 안에 있는 아키텍처가 가용성, 성능을 어떻게 보장해 주는지 말해주지 못하면 안되기에 아키텍처를 보다 살펴보고 발전방향을 따라가야 겠다는 생각이 든다.
당장은 ksqlDB가 ksql + connect를 포함하는 구조이기에 정말로 별로로 운영 중인 ksql + connect와 동일한 운영이 가능한지 비교해 볼 필요가 있겠다.
반응형