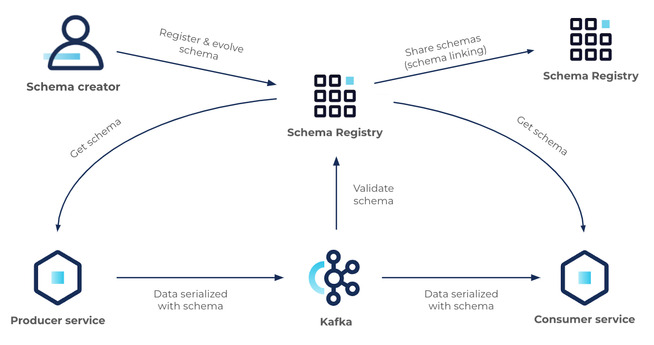
이번 글에서는 schema registry를 HA로 설정하는 방법에 대해서 설명한다. 하지만 HA를 구성하기 위한 설정은 생각보다 단순하기 때문에 schema registry에 대해서 대략적으로 소개한다. 그리고 설치가 완료된 schema registry를 사용해서 카프카에 avro 포맷으로 데이터를 보내고 읽는 kafka-avro-console-producer와 kafka-avro-console-consumer를 사용해서 테스트하는 방법까지 해보자. 1. 개요 먼저 schema registry에 대해서 간략히 설명한다. 한 문장으로 설명하면 카프카에 기록할 메시지의 데이터 스키마를 관리하고 검증하는 서비스이다. 스키마를 관리하고 검증한다고 표현했는데 관리는 스키마를 기록하고 유지하는 역할이며, 검증은 ..