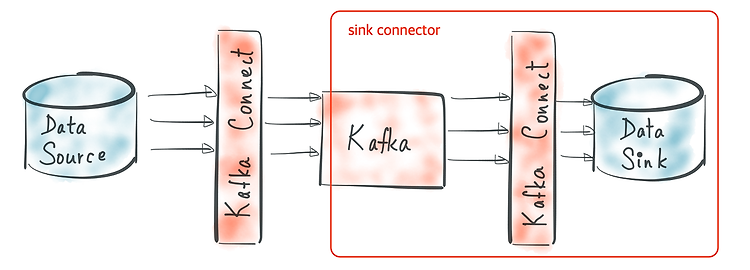
이번 글에서는 Kafka Connect를 쿠버네티스(이하 K8s)에서 구축하기 위해 도커 이미지를 만드는 방법에 대해서 설명하려고 한다. 이 말을 들었을 때, "왜 이미지를 따로 만들지?"라고 생각할 수 있다. 왜냐하면 컨플루언트에서 제공하는 도커 이미지가 있기 때문이다. 하지만 필자는 직접 이미지를 만들기로 했다. 이유는 Kafka Connect 내에 따로 개발한 Connector들을 빌드할 때, 해당 Connector들을 포함한 Kafka Connect 도커 이미지를 만들고 싶었다. 그리고 현재 운영 중인 환경과 동일한 버전으로 구성된 도커 이미지를 만들어서 환경 차이에 따라 혹시 발생할지 모르는 문제를 피하고 싶었기 때문이다. 그럼 도커 이미지를 만드는 내용에 들어가기 앞서 왜 쿠버네티스 환경에서 ..