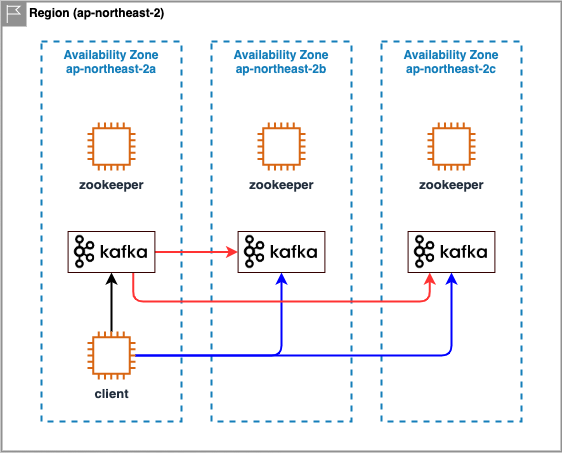
MirrorMaker2 소개 발표 2022년 4월 14일. Kafka 한국 사용자 모임 Virtual Meetup에서 발표를 했습니다. 주제는 MirrorMaker2 소개 입니다. MirrorMaker2를 처음 들어보시는 분들에 맞춰서 기초적인 내용을 포함하여 자료를 준비했습니다. MirrorMaker2의 아키텍처, 활용, 모니터링, 운영 팀의 목차로 구성되었습니다. Kafka 한국 사용자 모임 Github에도 올라갈 예정이나 먼저 블로그에 자료 공유합니다. Big Data/Kafka 2022.04.15
[Kafka] Avro Consumer의 GenericRecord schema 이번 글에서는 KafkaAvroDeserializer를 사용한 컨슈머에 대해서 이야기하려고 한다. KafkaAvroDeserializer를 사용했다는 것은 Schema-Registry(이하 스키마 레지스트리)를 사용했다는 의미이다. 스키마 레지스트리를 간단히 설명하면 Confluent에서 제공한 Schema 관리 시스템이다. 카프카로 들어오는 레코드들의 버전 관리가 필요할 때 스키마 레지스트리를 사용한다. 도입부에 많은 용어들을 나열했는데 기본적인 내용을 먼저 정리해야 이 글에서 이야기할 내용이 전달될 수 있을 듯 하다. 다음 용어들의 개념을 간단히만 살펴보고(자세한 내용은 링크 추가) 이해를 돕고자 한다. AVRO(이하 에이브로) 스키마 스키마 레지스트리 1. 에이브로 에이브로는 스키마, 스키마 레지스.. Big Data/Kafka 2021.12.30
[Kafka] MirrorMaker2 마이그레이션 업무가 많아서 기술 정리를 하지 못했었는데 오랜만에 블로그 글을 작성해 본다. 이번글에서는 MirrorMaker2(이하 MM2) 관련 내용을 소개한다. 최근 MM2로 미러링을 하던 카프카 클러스터의 이전을 계획하면서 MM2가 미러링 처리한 시점을 확인해야 했고, 이전 시점에 MM2에 처리한 토픽의 오프셋 이후부터 다시 미러링하도록 작업해야 했다. 그래서 MM2에서 미러링 처리한 데이터의 토픽/오프셋을 어떻게 관리하고, MM2를 새로 시작하거나 이전할 때 앞서 처리한 오프셋의 위치를 확인해 다시 미러링을 하는지 분석하게 되었다. 이번 글에서는 MM2 이전을 하는 과정에 포커스를 맞추지만 MM2의 오프셋 관리방식도 같이 소개한다. 1. MM2 구동시 시작되는 Connector MM2는 기본적으로 Kafka .. Big Data/Kafka 2021.05.21
MSK (Amazon Managed Streaming for Apache Kafka) vs EC2 직접 설치 비교 이번 글에서는 Amazon에서 제공하는 카프카 관리 서비스인 MSK와 EC2에서 직접 카프카를 설치했을 때의 장단점을 평가한다. 비교를 하게 된 목적은 AWS에서 데이터 처리를 위해 카프카가 필요할 때, 관리형 서비스인 MSK를 쓰면 편리하겠지만 가성비 관점도 포함하여 서비스 선택 시 도움이 되었으면 해서였다. 먼저 MSK를 생성하면 어떤 구조로 이루어져 있는지 보고 동일한 고가용성(HA)으로 EC2에 직접 카프카를 설치하는 방법을 소개한다. 그리고 구축한 MSK, EC2에서 동일한 트래픽의 데이터를 처리할 때 비용 계산을 한다. 마지막으로 운영 효율성 측면에서 비교한다. 1. 아키텍처 1.1 MSK 먼저 MSK의 아키텍처를 보자. MSK도 결국은 카프카이기 때문에 AWS 상에서의 네트워크 구조만 보면 .. Cloud 2021.01.04
[kafka] kafka-producer-perf-test 오랜만에 글을 작성한다. 그래서 간단한 내용을 하나 소개한다. 테스트를 위해서 카프카에 임의의 트래픽을 발생할 수 있는데 kafka-producer-perf-test.sh command를 사용하면 된다. 이것을 살펴보자. kafka-producer-perf-test.sh을 파라미터 없이 실행하면 옵션 항목을 볼 수 있다. 주요한 옵션만 살펴보자. 파라미터 설명 --topoic 데이터를 보낼 토픽 --num-records 전송할 메세지의 개수 --throughput 대략적인 messages/sec으로 처리량을 조절한다. -1을 설정할 경우 처리량 조정없이 계속 보낸다. --producer-props 프로듀서 설정. 필수 설정인 bootstrap.servers 등을 넣을 수 있다. --record-size .. Big Data/Kafka 2020.12.18
[Kafka] Burrow 인증 설정 이번글에서는 Burrow에 관한 글을 쓰고자 한다. Burrow는 Kafka consumer group의 LAG을 모니터링 할 때, 가장 많이 사용하는 어플리케이션 중에 하나이다. Burrow에 대한 설명과 간단한 사용법에 대한 내용은 다른 글들이 많이 존재해서 필자는 최근 인증과 관련된 설정 추가와 관련해서 추가 검토했던 사항 위주로 설명하고자 한다. 그렇다고 Burrow에 대한 설명을 제외하면 기술할 내용에 대한 이해가 떨어질 수 있어 간략한 설명은 한다. 1. Burrow란? Burrow는 링크드인에서 처음 개발한 오픈소스이다. Github readme의 처음 제목을 보면 다음과 같다. Burrow - Kafka Consumer Lag Checking Burrow의 사용 목적은 Consumer La.. Big Data/Kafka 2020.10.16
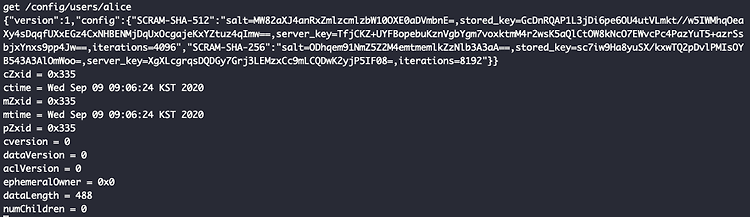
[Kafka] SASL/SCRAM 인증 이번글에서는 SCRAM 인증에 대해서 살펴보고자 한다. 앞선 2개의 글(SASL/PLAIN, Kerberos) 에서 SASL 인증을 사용했을 때, 대략적인 설정 방법은 비슷하기 때문에 참고하면 좋다. 그래서 이 글에서는 SCRAM의 특징과 다른 인증과의 차이점이 무엇인지 살펴보면 의미가 있을 것 같다. 1. SCRAM? SCRAM은 Salted Challenge Response Authentication Mechanism의 약칭이다. 간단히 설명하면 전통적인 사용자/비밀번호를 통해 인증을 처리하는데 비밀번호를 암호화해서 저장하는 방식이다. 카프카에서는 SCRAM-SHA-256과 SCRAM-SHA-512를 지원한다. 카프카는 SCRAM의 기본 저장소로 주키퍼를 사용한다. 실습을 진행하면서 주키퍼에 어떻게 .. Big Data/Kafka 2020.09.09
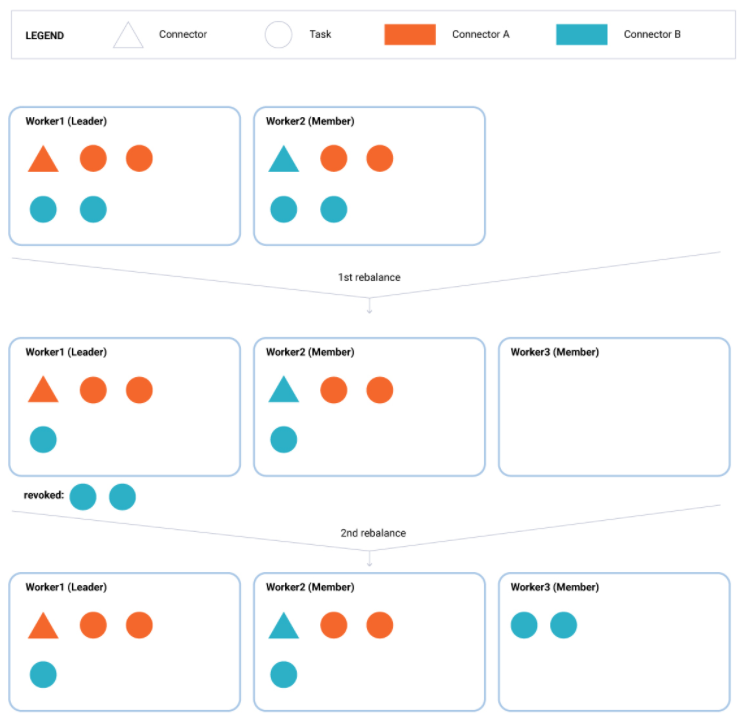
[Kafka] Incremental Cooperative Rebalancing in Apache Kafka (Connect) Kafka Connect와 관련되어 가장 중요한 업데이트라고 생각되는 Incremental Cooperative Rebalancing에 대해서 설명한다. 필자가 가장 중요하다고 생각하는 이유는 Connect 운영하면서 제일 심각한 문제로 생각되던 부분이 개선되었기 때문이다. 개선이 된 부분은 컨슈머의 리밸런싱 동작과 연관이 있다. 그럼 변경되기 이전의 동작방식과 비교하면서 Incremental Cooperative Rebalancing를 이해해보자. 1. 2.3.0 이전 Connect 리밴런싱 전략 이번 글에서 설명하는 Incremental Cooperative Rebalancing는 2.3 버전에서 소개되었다. 그럼 그 이전 버전에서는 커넥트 컨슈머의 리밸런싱이 어떻게 이루어졌는지 보자. 먼저 결론을 .. Big Data/Kafka 2020.08.31
[Kafka] Add connector contexts to Connect worker logs Kafka Connect(이하 커넥트) 2.3.0 개선사항에 대한 두 번재 글이다. Logging 개선에 대해서 살펴본다. 기존 커넥트의 로그는 커넥트에 포함된 작업의 로그들이 구분되지 않고 뒤섞여서 확인하기 쉽지 않았다. 특히 리밸런스 과정이 일어나면 커넥트가 담당하는 파티션들이 변경되는데 로그가 구분이 안되니 어떤 작업이 진행중인지 명확하게 알 수 없었다. KIP-449: Add connector contexts to Connect worker logs을 통해서 커넥트에 포함된 작업들의 로그를 쉽게 분리해서 볼 수 있다. 적용하는 방법은 간단하다. 기존 connect log4j 설정의 패턴을 다음과 같이 바꾸면 된다. # 과거 버전 설정 log4j.appender.stdout.layout.Conver.. Big Data/Kafka 2020.07.22
[Kafka] Connector-level producer/consumer configuration overrides Kafka 2.3.0 버전에서는 Connect(이하 커넥트) 관련 개선사항이 많았다. 관련 내용을 계속 정리해 갈 예정인데, 첫 번째 글로 KIP-458: Connector Client Config Override Policy에 대해서 정리한다. KIP(Key Improvement Proposals) 문서 제목에서 알 수 있듯이 Connector에 포함된 Client(Producer, Consumer)의 설정을 override 할 수 있게 되었다. 필자가 해당 내용에 대해서 관심을 갖게 된 이유는 커넥트에 포함된 Sink Connector들의 Source 카프카 클러스터가 하나로만 유지할 수 있어 여러 카프카 클러스터를 보유했을 경우, 커넥트 클러스터도 여러개를 구축해야 했다. 그런데 커넥트의 컨슈머 설.. Big Data/Kafka 2020.07.21
[Kafka] 카프카 클러스터에 적당한 토픽/ 파티션 개수는? 카프카 관리자 업무를 진행하면서 가장 많이 받는 질문 중 하나는 "파티션 개수는 몇 개가 적당합니까?"이다. 그래서 이번 글은 Confluent 공동 창업자 중 한명인 Jun Rao가 쓴 How to choose the number of topics/partitions in a Kafka cluster? 라는 블로그 글을 인용해서 파티션 숫자와 관련하여 정리한다. 필자의 글은 Jun Rao의 글을 바탕으로 이해한 부분들을 풀어서 썼기 때문에 해당 주제에 관심이 있는 분들은 Jun Rao의 원문을 다시 읽어보시길 추천한다. 많은 파티션은 높은 처리량을 이끈다. 카프카에 기본적인 지식을 가지고 계신 분이라면 카프카가 분산 처리의 목적으로 설계되었음을 안다. 카프카의 분산 처리를 가능하게 하는 핵심 개념이 토.. Big Data/Kafka 2020.07.20
[Kafka] Connect distributed mode 참고사항 이번글은 Kafka Connect를 distributed mode로 사용할 때 필자가 실수했던 내용을 공유하는 목적이다. Kafka Connect는 Standalone, Distributed 2가지의 mode가 있다. 테스트나 로컬에서 데이터를 이동할 때는 Standalone을 사용하지만 대부분의 운영 상황에서는 Distributed mode를 사용하게 된다. 필자의 실수에 대한 내용을 간략히 기술하면 다음과 같다. Custom한 Connector를 개발한 이후, Connect에 plugin을 배포하고 실행했다. REST API로 하나의 Job을 실행했다. 정상적으로 동작했다. 여러개의 Job의 동작 유무를 확인하기 위해 추가로 Job을 실행했다. 에러가 발생 에러의 내용은 다음과 같다. org.apac.. Big Data/Kafka 2020.07.07