Kafka Cluster를 관리하다 보면 필요에 의해 Topic을 생성했지만 현재는 사용하지 않아서 삭제할 Topic들을 찾아야 할 때가 있다.
Broker 설정 중에 자동으로 Topic을 생성해 주는 auto.create.topics.enable 옵션이 있는데 default 값이 true 이다.
auto.create.topics.enable=true의 의미는 Producer에 의해서 메세지를 Broker에 전송했는데, 존재하지 않는 topic에 메세지를 전송한 것이라면 해당 Topic을 자동으로 생성하는 것이다. 그래서 테스트를 위해서 여러 Topic에 무분별하게 계속 메세지를 발송했다면 사용하지 않는 Topic들이 늘어나게 된다.
이런 질문을 할 수 있다.
사용하지 않더라도 그냥 Topic을 남겨둬도 상관없지 않아요?
하지만 Topic을 계속 유지하면 성능에 영향을 미치게 된다.
Consumer는 모든 Replica에 복제가 완료된 데이터에 한해서 가져올 수 있다. confluent blog에서 소개하고 있는 한 실험에 의하면 1000개의 파티션을 복제하는데 대략 20ms의 시간이 걸린다.
즉 Consumer가 데이터를 받기 위해 20ms의 end-to-end latency가 걸린다는 의미이다.
만약 브로커가 가지고 있는 파티션의 수가 많다면 latency는 늘어나게 될 것이다.
추천하는 파티션의 수는 100 * b (브로커 수) * r (복제 수) 이다.
그럼 이번 글에서 말하고자 하는 본론에 들어가보자. 아래 2가지 단계로 간단한 아이디어를 설명한다.
-
데이터 사이즈 metric 수집
-
수집한 metric에서 특정 주기 동안 계속 데이터 사이즈가 0인 토픽 추출
1. 데이터 사이즈 metric 수집
먼저 삭제할 토픽을 추출하기 위한 근거 데이터를 수집하자. 수집할 대상은 토픽-파티션의 현재 데이터 사이즈이다.
Admin API를 보면 describeLogDirs 메서드가 존재한다. 파라미터로 브로커들의 ID 리스트를 전달하면 전달한 브로커들의 모든 로그 디렉토리 정보를 리턴한다.
아래 코드를 보면서 데이터 사이즈 metric을 어떻게 수집할 수 있는지 보자.
client.describeCluster 메서드를 통해서 kafka cluster에 포함된 id들을 가져다가 describeLogDirs에 파라미터로 던졌다.
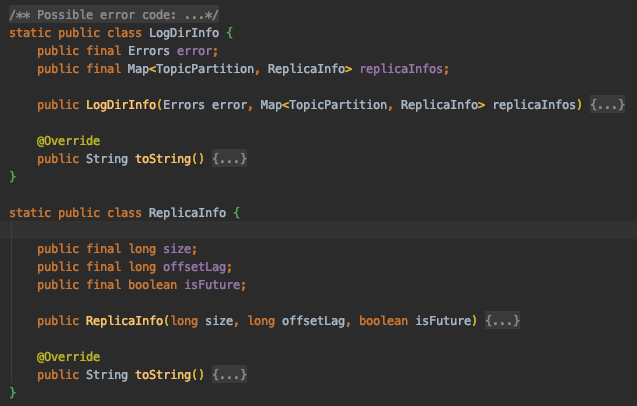
결과값은 디렉토리를 key로 LogDirInfo를 value로 갖는 Map을 리턴한다.
LogDirInfo가 가지고 있는 데이터를 쉽게 보도록 코드를 캡쳐했다.
결과적으로 ReplicaInfo의 size로 각 파티션별 데이터 사이즈를 알 수 있다.
필자의 경우는 Kafka Metric 저장소로 influxDB를 사용하고 있어서 위 코드 처럼 각 파티션의 데이터 사이즈를 뽑아서 주기적으로 저장했다.
2. 수집한 metric에서 특정 주기 동안 계속 데이터 사이즈가 0인 토픽 추출
두번째 단계의 아이디어는 간단하다.
현재 시점 (metric 저장 마지막 값)의 데이터 사이즈가 0인 토픽들을 대상으로 일정 기간 동안 데이터 사이즈의 합이 0이라면 해당 토픽은 사용하지 않는 것으로 간주한다.
그래서 metric 저장소에 따라 방법이 달라질 수 있다.
필자의 경우는 python 코드로 influxDB에 쿼리를 날려서 토픽들을 추출하는 방법을 사용했다.
참고로 influxDB에 저장한 데이터의 형태는 다음과 같다.
토픽 - 파티션 - 브로커 ID 값을 tag key로 주어서 관리했다. influxDB 대한 설명은 글의 범위를 벗어난 것이라 더 자세히 하진 않는다.

그럼 코드를 보자.
코드에서 크게 2개의 함수가 토픽을 분류하는 역할을 한다.
-
get_zero_topics : 현재(5분 이전) 기준으로 데이터 사이즈가 0인 토픽을 추출한다.
-
check_zero_topic : 현재 데이터 사이즈가 0인 토픽들을 대상으로 7일 전부터 데이터 사이즈 합이 0인 토픽을 필터링한다.
influxDB 쿼리의 시간조건을 변경하면 데이터 사이즈가 0인 기간을 조정할 수 있다.
필자는 제거하기 위한 토픽을 찾으려고 대략적인 아이디어서 만든 코드라 부족해 보일 수 있다.
그래도 해당 내용을 참고해서 토픽 관리에 도움이 되었으면 한다.
참고 문서
'Big Data > Kafka' 카테고리의 다른 글
| [Kafka] Connect distributed mode 참고사항 (0) | 2020.07.07 |
|---|---|
| [Kafka] Producer config 정리 (1) | 2020.06.16 |
| [Kafka] Kerberos 인증 #2 (2) | 2020.02.05 |
| [Kafka] Kerberos 인증 #1 (0) | 2020.02.03 |
| [Kafka] Introducing ksqlDB (0) | 2019.11.21 |