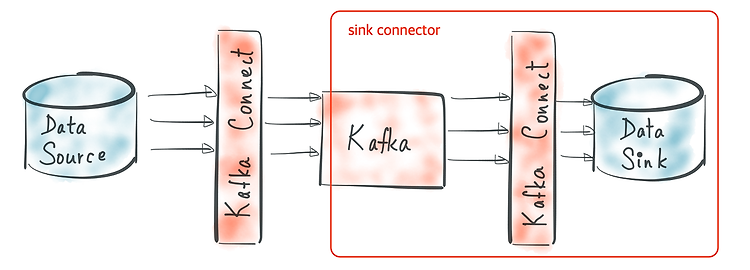
이번글에서는 SCRAM 인증에 대해서 살펴보고자 한다. 앞선 2개의 글(SASL/PLAIN, Kerberos) 에서 SASL 인증을 사용했을 때, 대략적인 설정 방법은 비슷하기 때문에 참고하면 좋다. 그래서 이 글에서는 SCRAM의 특징과 다른 인증과의 차이점이 무엇인지 살펴보면 의미가 있을 것 같다. 1. SCRAM? SCRAM은 Salted Challenge Response Authentication Mechanism의 약칭이다. 간단히 설명하면 전통적인 사용자/비밀번호를 통해 인증을 처리하는데 비밀번호를 암호화해서 저장하는 방식이다. 카프카에서는 SCRAM-SHA-256과 SCRAM-SHA-512를 지원한다. 카프카는 SCRAM의 기본 저장소로 주키퍼를 사용한다. 실습을 진행하면서 주키퍼에 어떻게 ..