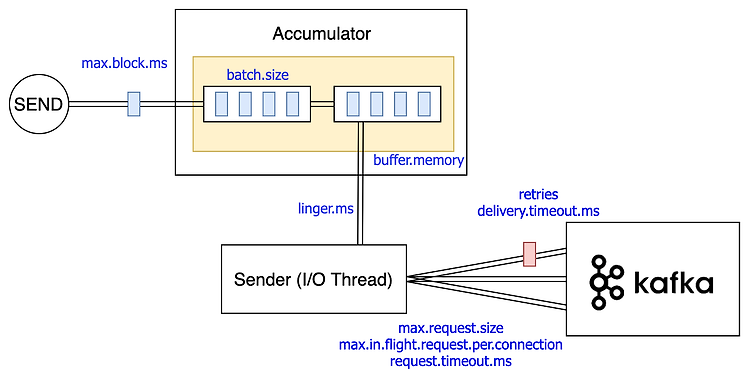
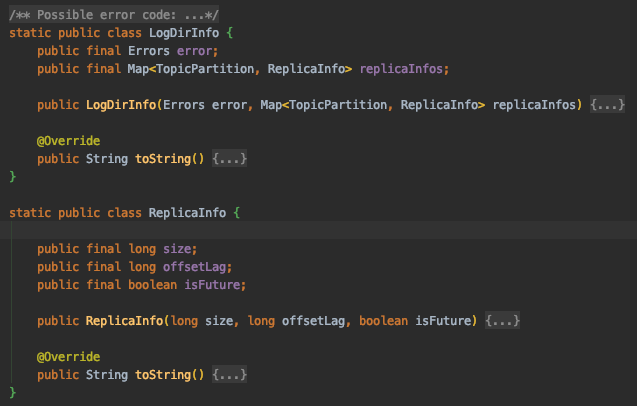
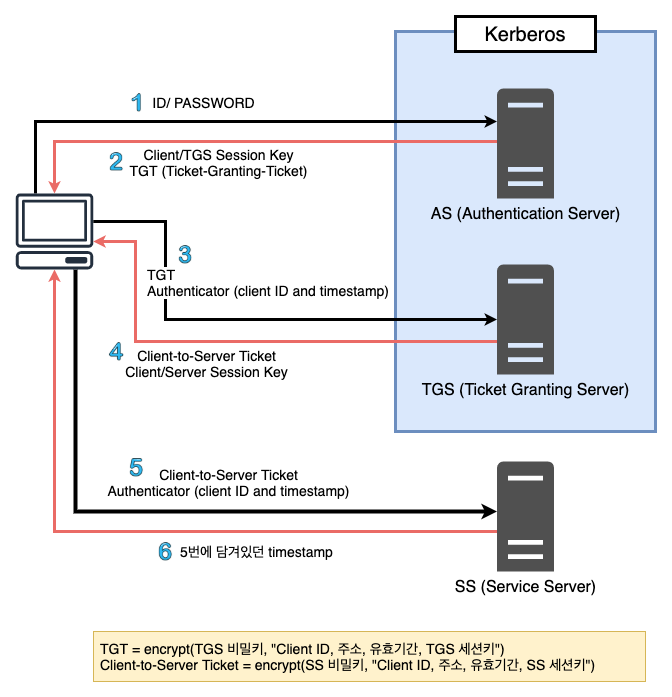
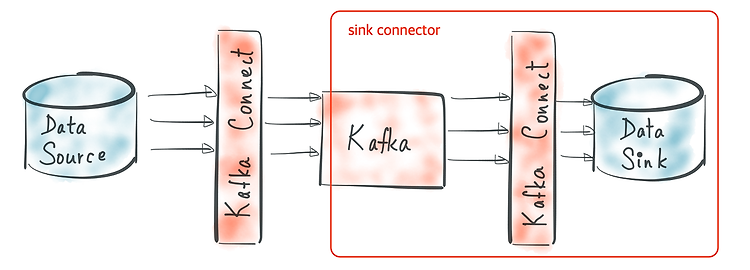
이번 글에서는 카프카 Producer(이하 프로듀서)의 주요 설정 값이 프로듀서의 아키텍처에서 어떤 역할을 하는지 정리한다. 카프카 문서에서는 각 설정값이 설명으로만 나열되어 있어서 이해하기 어려울 수 있다. 그래서 프로듀서의 주요 컴포넌트를 그림으로 표현하고 각 컴포넌트에서 어떤 설정 값을 사용해서 무슨 역할을 하는지 정리할 필요가 있다. 설정을 정리함에 있어서 카프카 문서를 제일 먼저 참조했지만 참고 문서에 포함한 내용도 추가해서 이해를 높이고자 했다. 1. 프로듀서 설정을 분석하는 이유 프로듀서의 정의를 사전에서 찾아보면 '생산자, 제작자'로 나온다. 카프카에서 프로듀서는 말 그래도 데이터를 생산하는 역할을 한다. 프로듀서의 설정값들은 데이터를 브로커에 발송할 때, 발송하는 데이터의 양/ 주기 및 ..