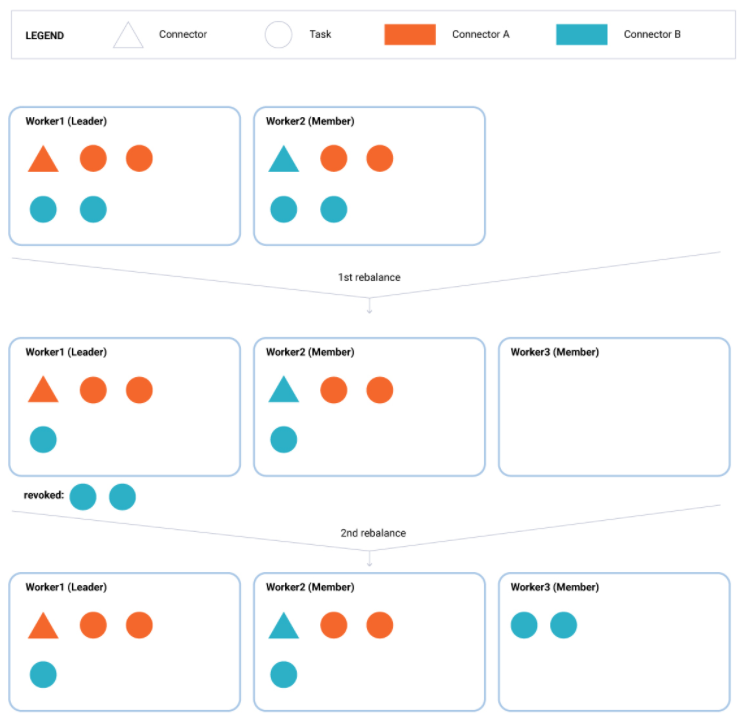
Kafka Connect와 관련되어 가장 중요한 업데이트라고 생각되는 Incremental Cooperative Rebalancing에 대해서 설명한다. 필자가 가장 중요하다고 생각하는 이유는 Connect 운영하면서 제일 심각한 문제로 생각되던 부분이 개선되었기 때문이다. 개선이 된 부분은 컨슈머의 리밸런싱 동작과 연관이 있다. 그럼 변경되기 이전의 동작방식과 비교하면서 Incremental Cooperative Rebalancing를 이해해보자. 1. 2.3.0 이전 Connect 리밴런싱 전략 이번 글에서 설명하는 Incremental Cooperative Rebalancing는 2.3 버전에서 소개되었다. 그럼 그 이전 버전에서는 커넥트 컨슈머의 리밸런싱이 어떻게 이루어졌는지 보자. 먼저 결론을 ..