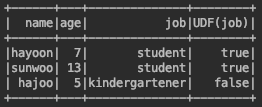
이번에는 간단한 주제로 글을 짧게 남겨보고자 한다. stream의 groupBy와 관련된 내용이다. 개발을 하다가 List에 있는 객체의 특정 값으로 groupBy를 했다. 문제는 groupBy된 결과가 group key로 사용한 값의 순서로 정렬이 되지 않은 부분이다. 데이터 가공의 결과로 group key 값으로 정렬을 해줘야 사용하는 측에서 용이했기 때문이다. 관련해서 java doc을 찾아보았더니 같은 groupBy 함수에서 argument가 다른 함수가 존재했다. public static Collector groupingBy( Function